Your agent is the most thoroughly documented system in your engineering org and yet you still can't answer simple questions.
No, Christopher McQuarrie has not asked me to direct the next instalment of Mission: Impossible, though I am keeping a keen eye on my inbox. Today, we are talking state secrets!
That is also not true. But I did spend many years building stuff and things (the OFFICIAL term) for British Intelligence, and the single most valuable thing I took away was not state secrets. Instead, it was a deeply troubling obsession with data.
“Is this person a credible threat?” is the canonical example, and a very difficult one to answer. Intelligence analysts are basically superhumans, capable of finding links between vast amounts of varied data, and one of the ways they do that is by layering context.
Data, data, everywhere.
That data is vast: signals intelligence, human intelligence, financial records, travel manifests, satellite imagery, and a mountain of open-source material. Some of it is a tidy database, some of it is a photograph, and some of it is words scrawled on a piece of paper. The scale is hard to picture: by the NSA’s own figures, it “touches” around 29 petabytes of data a day, which is equivalent to the entire Library of Congress being inspected nearly 3,000 times over, daily.
I hear you shouting, “Well Tyler, big tech companies have access to lots of data, so why is MI5 so special?” Beyond the legal implications and the fact that we don’t (yet) live in a Blade Runner-style dystopia, the reasons are structural. Broadly speaking, any one organisation only ever holds a single thin slice of the picture: what you searched, what you spent, or where you travelled. You can know someone’s entire spending history in perfect detail and still have no idea what any of it means. An intelligence agency exists precisely to sit above all those slices and join them, which is the part almost nobody else is mandated, or built, to do. The fusion, not the volume, is the whole point.
This is the core function of an intelligence agency: not simply to collect the data, but to surface the hidden correlations in vast pools of information. Which brings us, as everything eventually does, to AI agents.
Context really is king
Your agent is the most thoroughly documented system in your engineering org. Every prompt, every completion, every tool call, every retry is captured somewhere: traces in your observability tool, scores in your eval suite, rows in your dataset. And yet you still can’t answer simple questions. Why did it do that? Where did the behaviour come from? Who gave it a gun? The records are all there, sitting in separate systems, and nobody joins them up.
So we did exactly that. We built a context layer that joins all these things together: one grounded picture of how your agent is put together and what it actually does, assembled from your codebase and traces, then turned loose to power Overmind, our AI engineering copilot.
We start at the codebase, because that’s where the ground truth lives. Before Overmind touches a single trace, it reads the code the agent runs on and compiles a Capability Card: the tools the agent can call and their real contracts, its input and output schema, the prompts, and the expected output. That’s the agent at its raw logical level, taken from the source rather than inferred from behaviour. Skip it, as most tooling does, and a trace is just a behaviour with nothing behind it, leaving you to reverse-engineer intent from whatever the trace happened to capture.
Then we bring in the data and the traces. Every record of what the agent did is a context source: production traces, dataset rows, eval scores, all built into the same shape. For a dataset, that layer is the spine: format, schema, per-column distribution, label space, cohorts, hygiene problems, derived straight from the data.
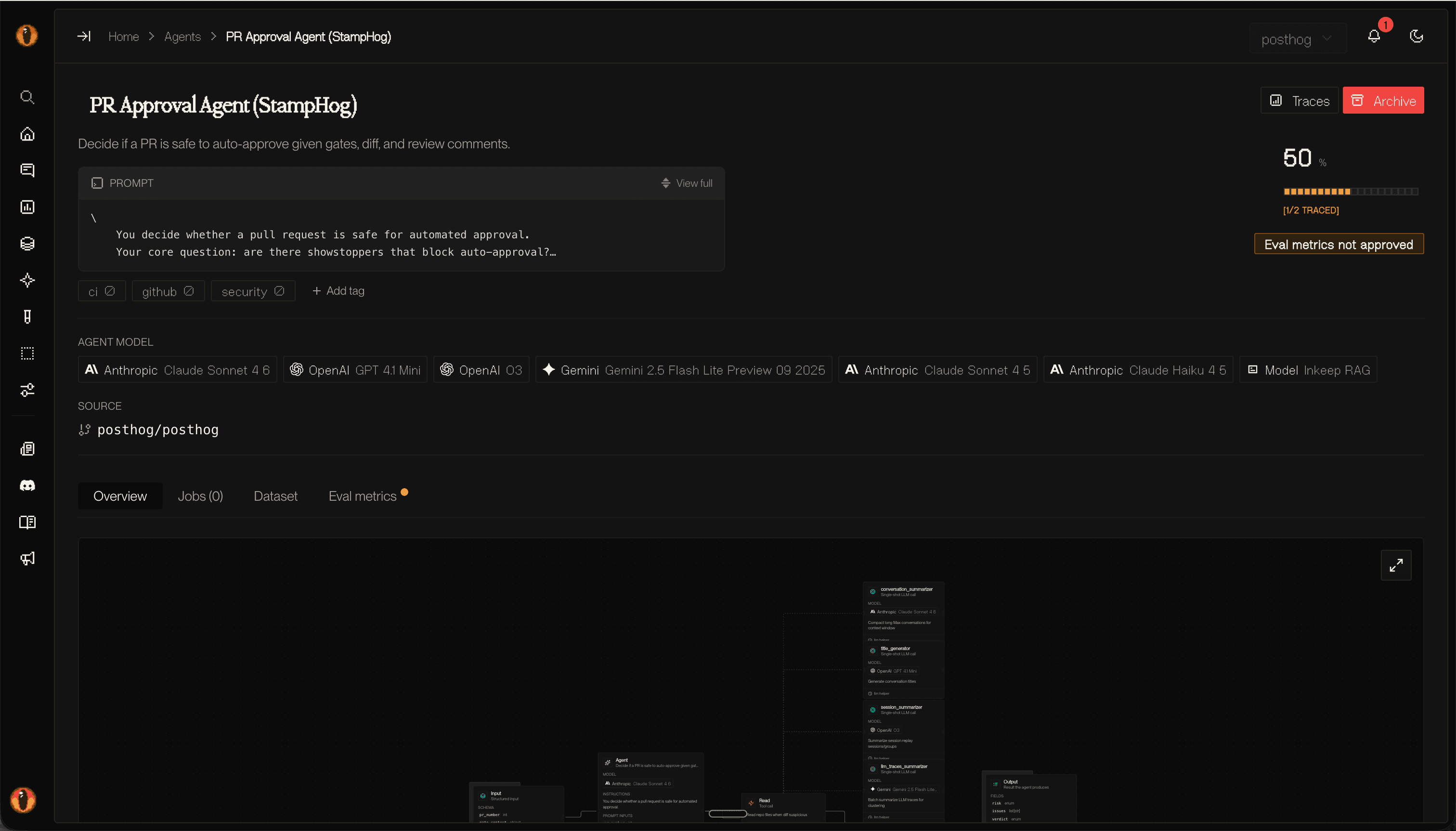
The codebase context is what makes that data useful. With the Capability Card in hand, Overmind knows the full surface of the agent and can measure the data against it: how much of that surface the data actually covers, which behaviours are well represented, which tools never appear, and which paths the agent takes in production that no dataset row touches. A pile of traces tells you what happened. The codebase tells you what could happen, and the gap between the two is the thing you need to see. That delta is what decides whether the data is good enough to evaluate against or train on, or whether you’re about to write evals for a fraction of the agent or fine-tune on the same narrow slice of its total behaviours.
Codebase tied to data tied to traces is the working surface for everything else we do. The data preprocessing reads from it, the evals are written against it, the fine-tuning sets are curated out of it, and the agent optimisation is steered by it. That’s the line between a tool that can tell you a behaviour was wrong and one that can tell you why, as well as how to fix it.
So, what do you know about your agent?
So much, maybe too much. But not in a useful way.
That is what Overmind is built for: not more raw evidence, but the relationships between it. Code, traces, datasets, evals, and training runs joined into one grounded view of the agent, so you can see what is really happening and where the gaps are.
Tyler Edwards is Co-Founder and CEO of Overmind. He writes about agent infrastructure, fine-tuning, and what it takes to ship AI that actually improves in production. Connect on LinkedIn.